Research Overview
Large-Scale Scene 3D Reconstruction and Understanding
 3D Reconstruction of UCAS
3D Reconstruction of UCAS
We focus on 3D computer vision research, especially focus on large-scale scene 3D reconstruction and understanding. Here is a brief introduction to our research work.
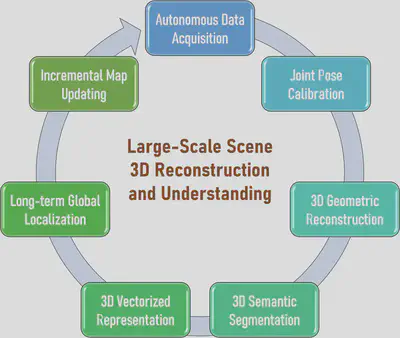
A complete large-scale scene 3D reconstruction and understanding system includes autonomous data acquisition, joint pose calibration, 3D geometric reconstruction, 3D semantic segmentation, 3D vectorized representation, long-term global localization, and incremental map updating. These modules form a closed-loop system in a progressive manner as shown in Figure 1. Below, we briefly describe the main research content of each key module in the 3D reconstruction and understanding system.
Autonomous Data Acquisition: Data acquisition is the first step in 3D reconstruction and understanding system, which directly affects the computational accuracy and stability of subsequent steps. The purpose of autonomous scene data acquisition is to use robots to autonomously collect massive data of large-scale complex scenes to achieve a complete coverage of the scene, while avoiding the subjectivity, experience and irreproducibility of manual data collection. This research includes robot global route dynamic planning, local aera discovery and exploration, optimal acquisition viewpoint selection, scene data coverage evaluation, etc.

Joint Pose Calibration: After acquiring massive scene data, the purpose of joint pose calculation is to calculate the precise spatial pose of the sensor at each moment in a unified coordinate system, so as to achieve spatio-temporal alignment of massive data. Especially when we collect data from multiple platforms (UAVs, unmanned vehicles, robots, etc.) and multiple modes (images, lasers, millimeter waves), accurate sensor pose calibration is critical for subsequent multi-mode integrating reconstruction and understanding. This research includes cross-modal data matching, robust scene graph construction, incremental and global scene reconstruction, online SLAM and offline SfM fusion, device-cloud collaborative reconstruction, etc.

3D Geometric Reconstruction: After obtaining the accurate spatial pose of the sensor at each moment, the purpose of 3D geometric reconstruction is to calculate a complete and accurate 3D geometric model of the scene. The geometric model here may be a dense 3D point cloud, a dense triangular mesh, or a dense 3D textured mesh. The geometric model is a 3D digitization of the real world, which is a reconstruction of the overall structure and local details of the scene. This research includes multi-view dense matching, multi-mode point cloud fusion, point cloud meshing and texture mapping, etc.

3D Semantic Segmentation: After obtaining the complete 3D geometric model of the scene, the purpose of 3D semantic segmentation is to obtain the semantic attributes of each geometric primitive (point/facet) in the 3D model, and parse the scene into semantic components with different attributes (buildings, roads, bridges, vegetation, vehicles, etc.) to achieve 3D understanding of large-scale complex scenes. This research mainly explores 3D segmentation networks used for 3D data, segmentation methods based on fusion of 2D images and 3D geometry, cross-domain and cross-scene adaptation of pre-trained segmentation models, etc.

3D Vectorized Representation: After decomposing the scene into different semantic parts, the purpose of 3D vectorized representation is to transform a specific semantic component (such as a single building, a single road, a single floor, etc.) into a highly structured, highly compact, and standard-compliant vectorized representation, such as CAD model or BIM model. This research includes the structural decomposition of semantic components, the global regularization of the main structure, the global consistent assembly of structural components, the inference of component topological relations, etc.
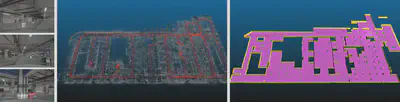
Long-term Global Localization: The reconstructed 3D geometric/semantic/vectorized 3D model could be further used as a global map to provide the ability of global localization for robots entering the scene. The purpose of long-term global localization is to compute the 6-DoF pose of a robot based to the correspondence between the robot real-time data and the 3D map. According to the different sensors used by the robot, the localization algorithm is also different, and the most challenging one is the visual localization problem based on a single image. This research includes all-weather and all-time visual localization, semantic visual localization, multi-source fusion localization, etc.
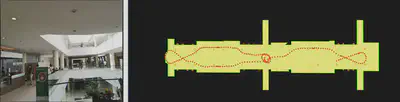
Incremental Map Updating: The constructed 3D map may change over time, and the purpose of incremental map updating is to discover and update the changed areas in the scene. Since the cost of updating a large-scale 3D map as a whole is very high, it is usually only necessary to perform local incremental updates for the changed areas. This research mainly explores the accurate registration of local and global maps, the change detection method of 3D maps, the reliability measurement of changed regions, and the map incremental update method. The updated 3D map could be returned to the first module again to start a new round of scene data acquisition.

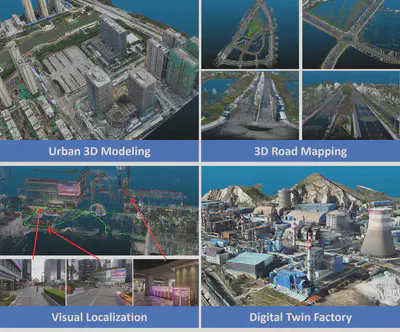
The above modules are connected in series to form a complete large-scale 3D scene reconstruction and understanding system, supporting practical applications in smart cities, unmanned systems, intelligent manufacturing, augmented reality and other fields, such as 3D modeling of urban scenes, 3D mapping for unmanned vehicles, visual localization for indoor and outdoor scenes, industrial 3D digital twins, etc. Figure 9 shows several typical applications that we have carried out.