三维视觉研究组研究概述
大规模复杂场景三维重建与理解
 国科大雁栖湖校区三维重建
国科大雁栖湖校区三维重建
我们长期以来专注于三维计算机视觉研究,尤其是面向大规模复杂场景的三维重建与理解,如下是我们研究内容的简介。这份简介用来帮助想加入我们团队的同学快速了解我们的研究方向,以及未来可能开展的研究内容。
一个完整的大规模复杂场景三维重建与理解系统包含“自主式场景数据获取→高精度联合位姿解算→完整化三维几何重建→细粒度三维语义分割→结构化三维矢量表达→全天候长时定位定姿→高时效地图增量更新”等模块。这些模块以逐层递进的方式形成首尾相连的闭环系统,实现从数据获取,到场景重建,到语义表达,再到动态更新的完整流程,如图1所示。下面,我们简述大规模复杂场景三维重建与理解系统中每一个关键模块的功能及其主要研究内容。

自主式场景数据获取: 数据采集是场景三维重建和理解的第一个步骤,直接影响后续步骤的计算精度和稳定度。自主式场景数据获取的目的是使用机器人自主的完成大规模复杂场景的海量数据采集,以实现场景的完备数据覆盖,同时避免人工数据采集的主观性、经验性和不可复现性。这一研究主要探索大规模复杂场景数据采集中机器人最优全局路线的动态规划、局部区域的发现和探索、最优采集视点的选择、以及场景数据覆盖度的评估等。

高精度联合位姿解算: 当获取了海量场景数据后,高精度联合位姿解算的目的是在统一坐标系下计算每一时刻传感器的精确空间位姿,实现海量数据的时空对齐。尤其当我们采集了多种载具(无人机、无人车、机器人等)、多种模态(图像、激光、毫米波)的数据时,精确的传感器位姿解算对后续的多模融合重建和理解至关重要。这一研究主要探索跨模数据的匹配对应、场景图的高效构建、增量/全局式场景重建、在线SLAM与离线SfM融合、端云协同大规模高效重建等。

完整化三维几何重建: 当获得了每一时刻传感器精确的空间位姿后,完整化三维几何重建的目的是计算场景完整精确的三维几何模型。这里的几何模型可能是稠密三维点云、稠密三角网格、或者稠密三维纹理网格。三维几何模型实现了对场景三维几何结构和空间几何细节的重建,以实现对真实世界的精确三维数字化。这一研究主要探索多视图稠密匹配方法、多模多视角点云融合方法、点云网格化和纹理映射方法等。同时,在这一模块中几何视觉方法和端到端学习方法也开始发生深度融合。

细粒度三维语义分割: 当获取了场景的完整三维几何模型后,细粒度三维语义分割的目的是获取三维模型中每一个几何基元(点云/面片)的语义类别属性,将场景解析为不同属性的语义部件(建筑、道路、桥梁、植被、车辆等),以实现对大规模复杂场景的三维语义理解。这一研究主要探索各类针对三维几何模型的语义分割方法,包括直接用于三维数据的分割网络、基于二维图像和三维几何融合的分割方法、预训练分割模型的跨域跨场景适应等。

结构化三维矢量表达: 当获取了场景中不同类别的语义部件后,结构化三维矢量表达的目的是将单个语义部件(如单体建筑、单段道路、单个楼层等)转化为高度结构化、高度紧致化、且符合规范标准的矢量结构表达,如CAD模型或者BIM模型等,这也是绝大多数实际应用所需的最终三维模型形态。这一研究主要探索单体语义部件的结构分解、主体结构的全局规整化、结构部件的全局一致性组装、结构部件的拓扑关系推断等。结构化三维矢量表达通常可以将稠密三维点云/稠密三角网格模型体积压缩至原来的1%以内,且具有更好的结构性和规整性。
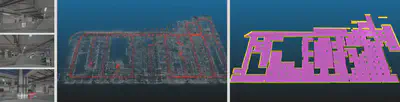
全天候长时定位定姿: 当获取了场景的三维几何/三维语义/三维矢量模型后,可以进一步作为全局定位地图,为进入场景的机器人和无人系统提供全局定位定姿的能力,全天候长时定位定姿的目的,就是根据无人系统采集的传感数据进行全局实时六自由度定位。这一研究根据无人系统使用的传感器不同,定位算法也不同,其中最具挑战性的是基于单幅图像的全局定位问题。长时定位定姿的研究内容包含全天候全时段视觉定位、基于矢量地图的语义视觉定位、多源传感器紧耦合滤波定位等。
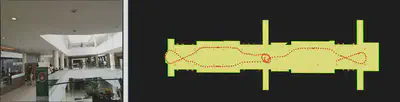
高时效地图增量更新: 已构建的三维地图可能随时间推移发生变化,高时效地图增量更新的目的是发现场景中出现变化的区域,并进行更新。由于对大规模场景三维地图进行整体更新的成本是很高的,所以通常只需要对变化的区域进行局部增量式更新。这一研究主要探索局部地图与全局地图的精确配准、三维地图的变化检测方法、变化区域的可信度与显著性度量策略、全局三维地图的增量更新等。更新后的三维地图可以再次返回给第一个模块,以实现机器人平台的全局定位以及新一轮的场景数据获取。

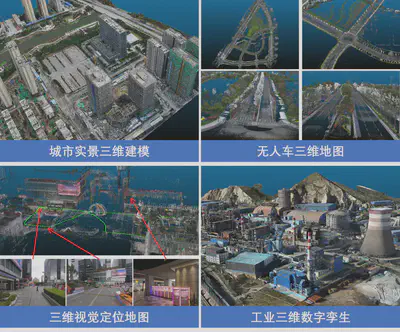
上述这些模块整体串联起来,构成了一个完整的大规模复杂场景三维重建与理解系统,支撑智慧城市、无人系统、智能制造、增强现实等领域的实际应用,包括城市实景三维建模、无人车三维高精地图构建、室内外场景三维重建与视觉定位、工业三维数字孪生等,图9显示了我们已开展几个典型应用。