Efficient 3D Scene Semantic Segmentation via Active Learning on Rendered 2D Images
Abstract
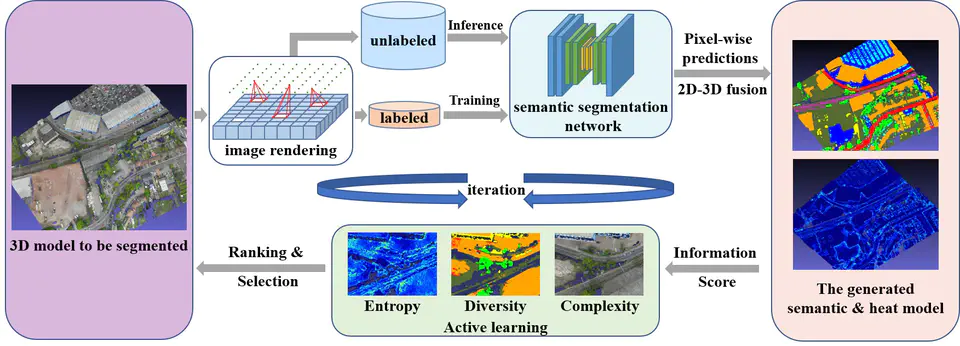
Inspired by Active Learning and 2D-3D semantic fusion, we proposed a novel framework for 3D scene semantic segmentation based on rendered 2D images, which could efficiently achieve semantic segmentation of any large-scale 3D scene with only a few 2D image annotations. In our framework, we first render perspective images at certain positions in the 3D scene. Then we continuously fine-tune a pre-trained network for image semantic segmentation and project all dense predictions to the 3D model for fusion. In each iteration, we evaluate the 3D semantic model and re-render images in several representative areas where the 3D segmentation is not stable and send them to the network for training after annotation. Through this iterative process of rendering-segmentation-fusion, it can effectively generate difficult-to-segment image samples in the scene, while avoiding complex 3D annotations, so as to achieve label-efficient 3D scene segmentation. Experiments on three large-scale indoor and outdoor 3D datasets demonstrate the effectiveness of the proposed method compared with other state-of-the-art.