摘要
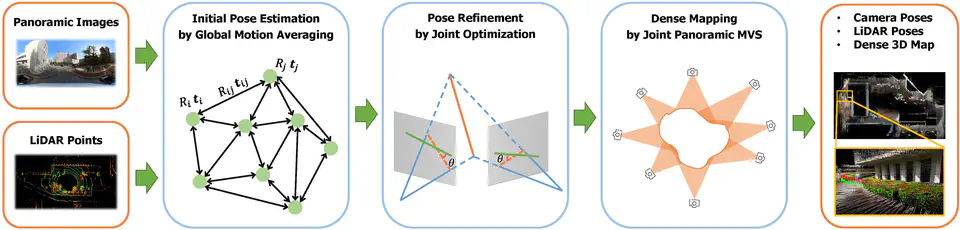
Cameras and LiDARs are currently two types of sensors commonly used for 3D mapping. Vision-based methods are susceptible to textureless regions and lighting, and LiDAR-based methods easily degenerate in scenes with insignificant structural features. Most current fusion-based methods require strict synchronization between the camera and LiDAR and also need auxiliary sensors, such as IMU. All of these lead to an increase in device cost and complexity. To address that, in this paper, we propose a low-cost mapping pipeline called PanoVLM that only requires a panoramic camera and a LiDAR without strict synchronization. Firstly, camera poses are estimated by a LiDAR-assisted global Structure-from-Motion, and LiDAR poses are derived with the initial camera-LiDAR relative pose. Then, line-to-line and point-to-plane associations are established between LiDAR point clouds, which are used to further refine LiDAR poses and remove motion distortion. With the initial sensor poses, line-to-line correspondences are established between images and LiDARs to refine their poses jointly. The final step, joint panoramic Multi-View Stereo, estimates the depth map for each panoramic image and fuses them into a complete dense 3D map. Experimental results show that PanoVLM can work on various scenarios and outperforms state-of-the-art vision-based and LiDAR-based methods.