VidSfM: Robust and Accurate Structure-from-Motion for Monocular Videos
摘要
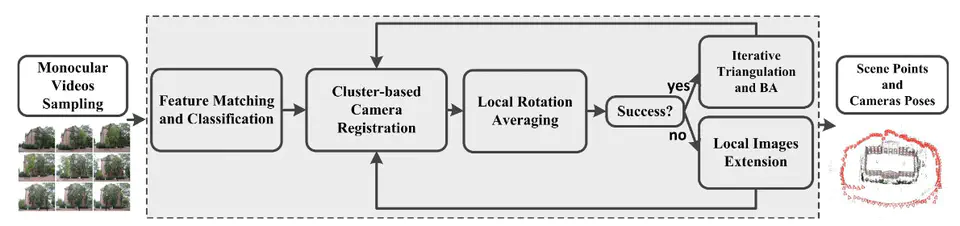
With the popularization of smartphones, larger collection of videos with high quality is available, which makes the scale of scene reconstruction increase dramatically. However, high-resolution video produces more match outliers, and high frame rate video brings more redundant images. To solve these problems, a tailor-made framework is proposed to realize an accurate and robust structure-from-motion based on monocular videos. The key ideas include two points: one is to use the spatial and temporal continuity of video sequences to improve the accuracy and robustness of reconstruction; the other is to use the redundancy of video sequences to improve the efficiency and scalability of system. Our technical contributions include an adaptive way to identify accurate loop matching pairs, a clusterbased camera registration algorithm, a local rotation averaging scheme to verify the pose estimate and a local images extension strategy to reboot the incremental reconstruction. In addition, our system can integrate data from different video sequences, allowing multiple videos to be simultaneously reconstructed. Extensive experiments on both indoor and outdoor monocular videos demonstrate that our method outperforms the state-ofthe-art approaches in robustness, accuracy and scalability.