Recalling Direct 2D-3D Matches for Large-Scale Visual Localization
摘要
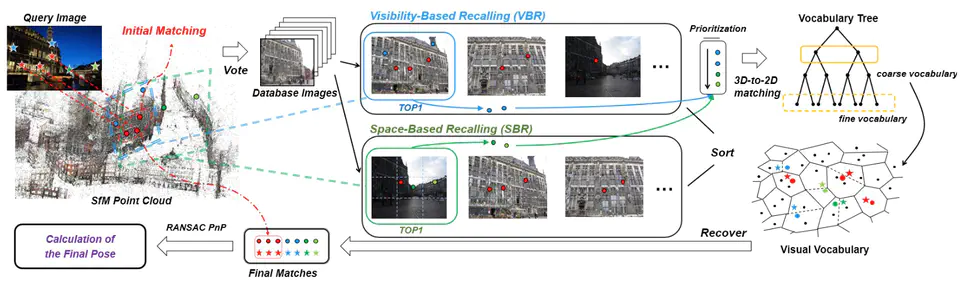
Estimating the 6-DoF camera pose of an image with respect to a 3D scene model, known as visual localization, is a fundamental problem in many computer vision and robotics tasks. Among various visual localization methods, the direct 2D-3D matching method has become the preferred method for many practical applications due to its computational efficiency. When using direct 2D-3D matching methods in large-scale scenes, a vocabulary tree can be used to accelerate the matching process, which will also induce the quantization artifacts leading to reduce the inlier ratio and decrease the localization accuracy. To this end, in this paper two simple and effective mechanisms, called visibility-based recalling and space-based recalling, are proposed to recover lost matches caused by the quantization artifacts, thus can largely improve the localization accuracy and success rate without increasing too much computational time. Experimental results on long-term visual localization benchmarks demonstrate the effectiveness of our method compared with state-of-the-arts.